This series of posts demonstrates efficient filtering and pagination with DynamoDB.
Part 1: Duplicating data with Lambda and DynamoDB streams to support filtering
Part 2: Using global secondary indexes and parallel queries to reduce storage footprint and write less code
Part 3: How to make pagination work when the output of multiple queries have been combined
Part 4: Storage and retrieval of comment statistics using index overloading and sparse indexes
The approach taken in previous post was not a perfect solution as a large number of redundant items were created by code that we would have to maintain.
In this post, we will improve upon our original model with more GSIs and parallel queries.
Previously, we had to create a Lambda function and use DynamoDB Streams. DynamoDB has built-in functionality that can achieve this: global secondary indexes.
In addition, there was a desire to keep the client program simple and get an answer from a single request to DynamoDB. If we relax that possibly misguided notion and allow ourselves to issue multiple queries in parallel, gathering and processing the small amount of returned data within our client, we might end up with a better model.
Let’s apply both approaches and see what happens.
Access patterns
Firstly let’s recap on the model we are building.
We are tasked with producing a data model to store and retrieve the comments shown on each product page within an e-commerce site. A product has a unique identifier which is used to partition the comments. Each product has a set of comments. The most recent
20comments are shown beneath a product. Users can click a next button to paginate through older comments. As the front end system might be crawled by search engines, we do not want performance to degrade when older comments are requested.
This can be broken down into the following access patterns.
- AP1: Show all comments for a product, most recent first
- AP2: Filter by a single language
- AP3: Filter by any combination of ratings from 1-5
- AP4: Show an individual comment
- AP5: Delete a comment
- AP6: Paginate through comments
Table design
To save space in the diagrams below, not all non-indexed item attributes such as the comment title, text and username are shown on the below diagrams.
languageandratingare shown to demonstrate non-key attributes being projected into GSIs.
Table
The below table contains three comments for product 42. To create a comment, a single item is written to the table with the keys shown. The write path is out of scope. Imagine it is an API that receives a POST request from a web or mobile client, generates an Item that conforms to our model and makes the PutItem call.
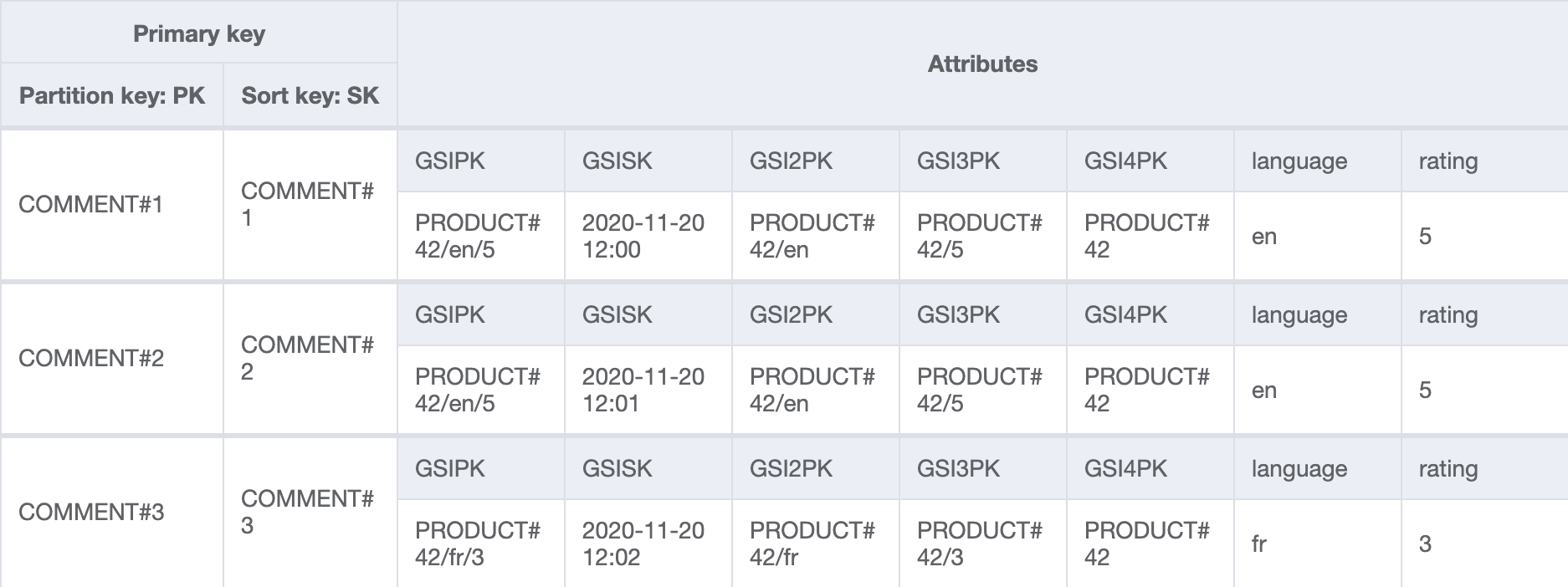
That’s a lot more than key attributes than last time! This is because items need to contain a key for each of the indexes they’re going to appear in. We reuse GSISK across all of the other indexes as it stores the creation date, the common sort key.
DynamoDB handles the projection of necessary keys and attributes into four other indexes on our behalf. Only a subset of attributes from the table are projected to save space and reduce query costs. This is shown in the following diagrams.
We form the partition key with this pattern:
PRODUCT#<identifier>[/<projected filter 1>/<projected filter 2>]
We populate the sort key with a sortable date string to ensure ordering. As seen above, we need to use slightly different partition keys to support a range of queries. Discussion around the keys used in each GSI is explained in the following sections.
GSI: byLangAndRating

The partition key contains the product identifier, comment language and rating. The date, a sortable string, is used as the sort key.
This index is suitable for getting all comments for a single language and single rating. Only a subset of attributes from the table are projected to save space and reduce query costs.
GSI 2: byLang
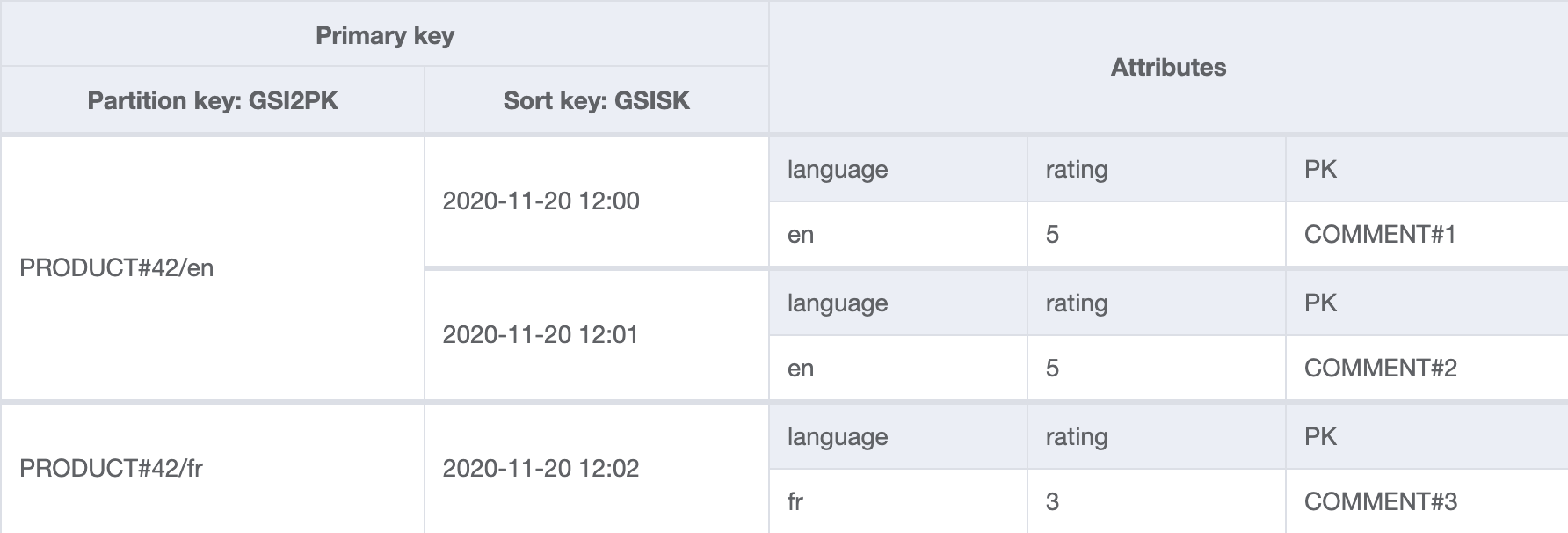
The partition key contains the product identifier and the comment language. The creation date (stored in GSISK) is used as the sort key.
This index is suitable for getting all comments for a given language, regardless of rating. This is the default state when a user visits each product page, so will see the most traffic.
GSI 3: byRating
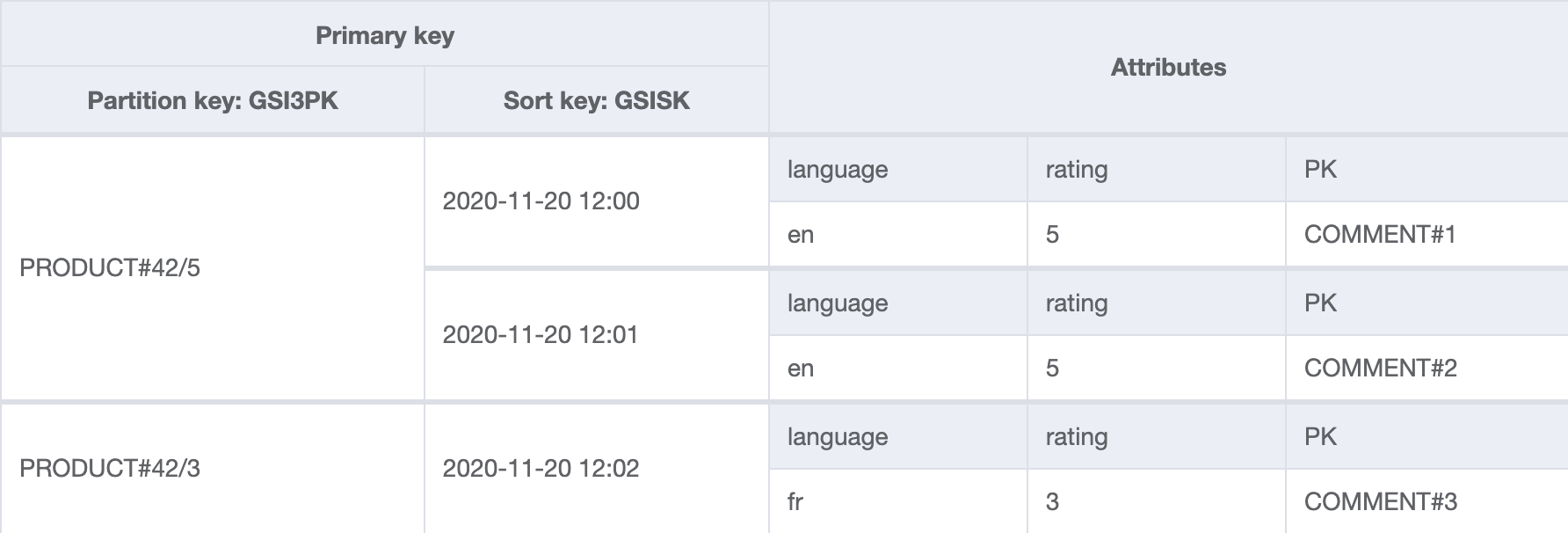
The partition key contains the product identifier and the comment rating. The creation date (stored in GSISK) is used as the sort key.
This index is suitable for getting all comments for a given rating, regardless of language.
GSI 4: all
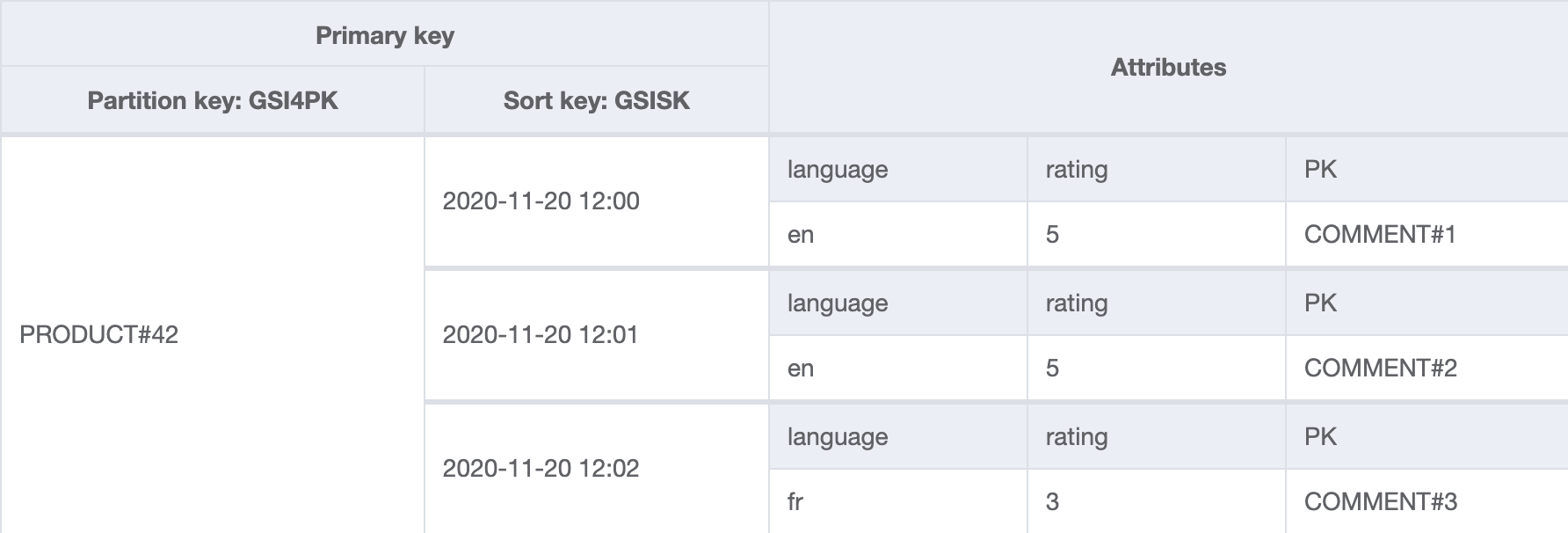
The partition key contains just the product identifier. The creation date (stored in GSISK) is used as the sort key.
As its name would imply, this index is suitable for getting all comments of any language and any rating.
Queries
All queries should have ScanIndexForward set to false in order to retrieve the most recent comments first, and a Limit of 20.
AP1: Show all comments for a product, most recent first
- Query on
all- GSI4PK =
PRODUCT#42
- GSI4PK =
AP2: filter by a single language
- Query on
byLang- GSI2PK =
PRODUCT#42/en
- GSI2PK =
AP3: Filter by any combination of ratings from 1-5
a. Single language
- Rating
2, 3 or 5in languageen- In parallel:
- Query on
byLangAndRating- GSIPK =
PRODUCT#42/en/2 - Limit =
20
- GSIPK =
- Query on
byLangAndRating- GSIPK =
PRODUCT#42/en/3 - Limit =
20
- GSIPK =
- Query on
byLangAndRating- GSIPK =
PRODUCT#42/en/5 - Limit =
20
- GSIPK =
- Query on
- Gather results into single collection, reverse sort on
GSISKand return top N
- In parallel:
b. Any language, single rating
- Rating
2- Query on
byRating- GSI3PK =
PRODUCT#42/2
- GSI3PK =
- Query on
c. Any language, multiple ratings
- Rating
3 or 5- In parallel:
- Query on
byRating- GSI3PK =
PRODUCT#42/2
- GSI3PK =
- Query on
byRating- GSI3PK =
PRODUCT#42/5
- GSI3PK =
- Query on
- In parallel:
AP4: Show a comment directly through its identifier
GetItemon table- PK =
COMMENT#100001 - SK =
COMMENT#100001
- PK =
AP5: Delete
DeleteItemon table- PK =
COMMENT#100001 - SK =
COMMENT#100001
- PK =
AP6: Paginate through comments
Run any of the above queries with Limit set to 20. Use LastEvaluatedKey returned by DynamoDB to paginate through results by passing it as ExclusiveStartKey in the next query request.
Pagination support for AP3 is slightly more complicated and will be covered in the next post.
Query planning
Logic is required to choose which access pattern is best suited to resolve a query based on the provided parameters.
For instance, given:
language=enrating=1 rating=2 rating=3 rating=4 rating=5
AP2 will be used as all ratings are specified, making the filtering a needless cost. The results will be the same for more work.
AP3a would be used if only rating=2 rating=4 are required.
If no filtering is specified, AP1 would be used.
The following code snippet demonstrates shows a basic implementation.
baseKey := "PRODUCT#" + productID
// Select strategy based on filter parameters. This tells us what index to use.
// Index name, PK and SK are encoded inside instances of Index, which we can query.
switch findStrategy(language, ratings) {
case all:
queryOutput, err = allIndex.Query(baseKey)
case allLangSingleRating:
queryOutput, err = byRatingIndex.Query(baseKey, ratings[0])
case langSingleRating:
queryOutput, err = byLangAndRatingIndex.Query(baseKey, language, ratings[0])
// ...etc
}
Databases have query planners. If you’ve ever prefixed a SQL query with EXPLAIN and tried to make sense of the output, you have just asked the database how it will satisfy your query. This is the work the database will do if it were to execute the query. Although the example above is a crude switch statement, it is performing the same role.
Given
inputuseindexwithkey(s).
This logic, along with any parallel query coordination (discussed in the next section), should be written once and provided to consumers either as a library or an API. This abstraction provides a high level interface to the model. We can also make improvements without needing consumers to change their code.
Parallel queries
Multiple ratings are required for AP3. Our design dictates that this is achieved by issuing multiple queries. Doing this in parallel can reduce latency. Modern languages make this fairly straightforward with goroutines, promises, or similar. An example is shown below.
// queryMultiple runs queries for every key in partitionKeyValues, combines the results, and returns the topN.
// If one of the queries fails, the whole call does.
func queryMultiple(index *DynamoIndex, partitionKeyValues []string) (*CommentQueryOutput, error) {
log.Printf("queryMultiple: pk=%s, pkValue=%s, indexName=%s", index.PK, partitionKeyValues, index.Name)
g, _ := errgroup.WithContext(context.Background())
queryOutputs := make([]*CommentQueryOutput, len(partitionKeyValues))
// Get multiple result sets for PRODUCT#42/3, PRODUCT#42/5 ...
for i, partitionKeyValue := range partitionKeyValues {
pkv := partitionKeyValue
idx := i
g.Go(func() error {
result, err := query(index, pkv) // Send query to DynamoDB
if err == nil {
queryOutputs[idx] = result
}
return err
})
}
// Wait for all to complete, cancel on first error.
if err := g.Wait(); err != nil {
return nil, err
}
// Combine and reverse sort the result sets and return topN.
var combined []CommentDynamoItem
for _, qo := range queryOutputs {
combined = append(combined, qo.Items...)
}
sort.Slice(combined, func(i, j int) bool {
return combined[i].GSISK > combined[j].GSISK
})
topN := combined[0:min(pageSize, len(combined))]
return &CommentQueryOutput{Items: topN}, nil
}
Building the table
There is nothing to do here. DynamoDB will handle the replication and keep the duplicated items in sync. Deleting a comment is now just a case of deleting the item from the table. This is a huge win, reducing the risk of inconsistencies while lowering costs.
It works!
A simple UI was built on top of this model. Notice how the query is resolved using different indexes and keys depending on the query parameters.
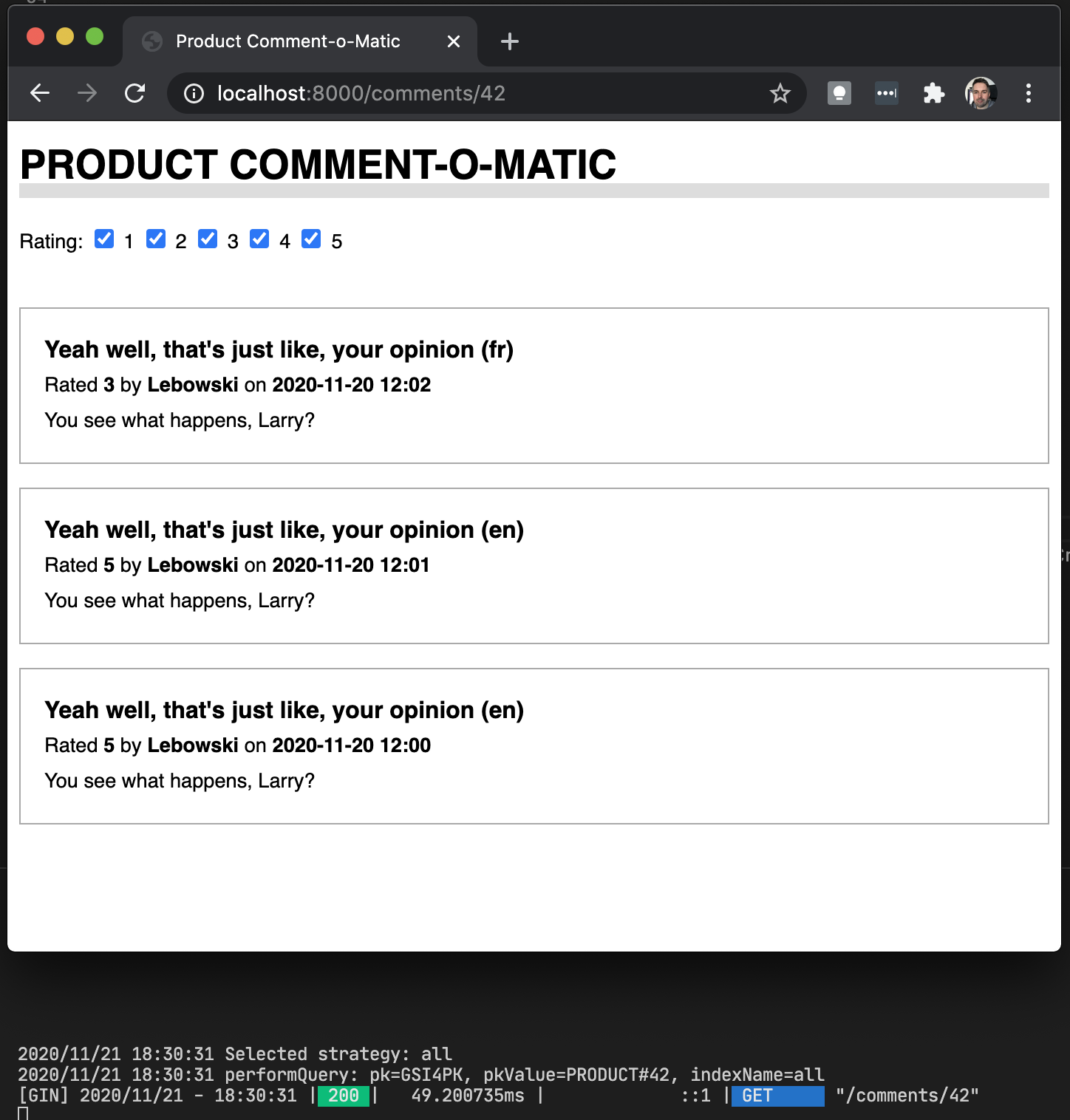
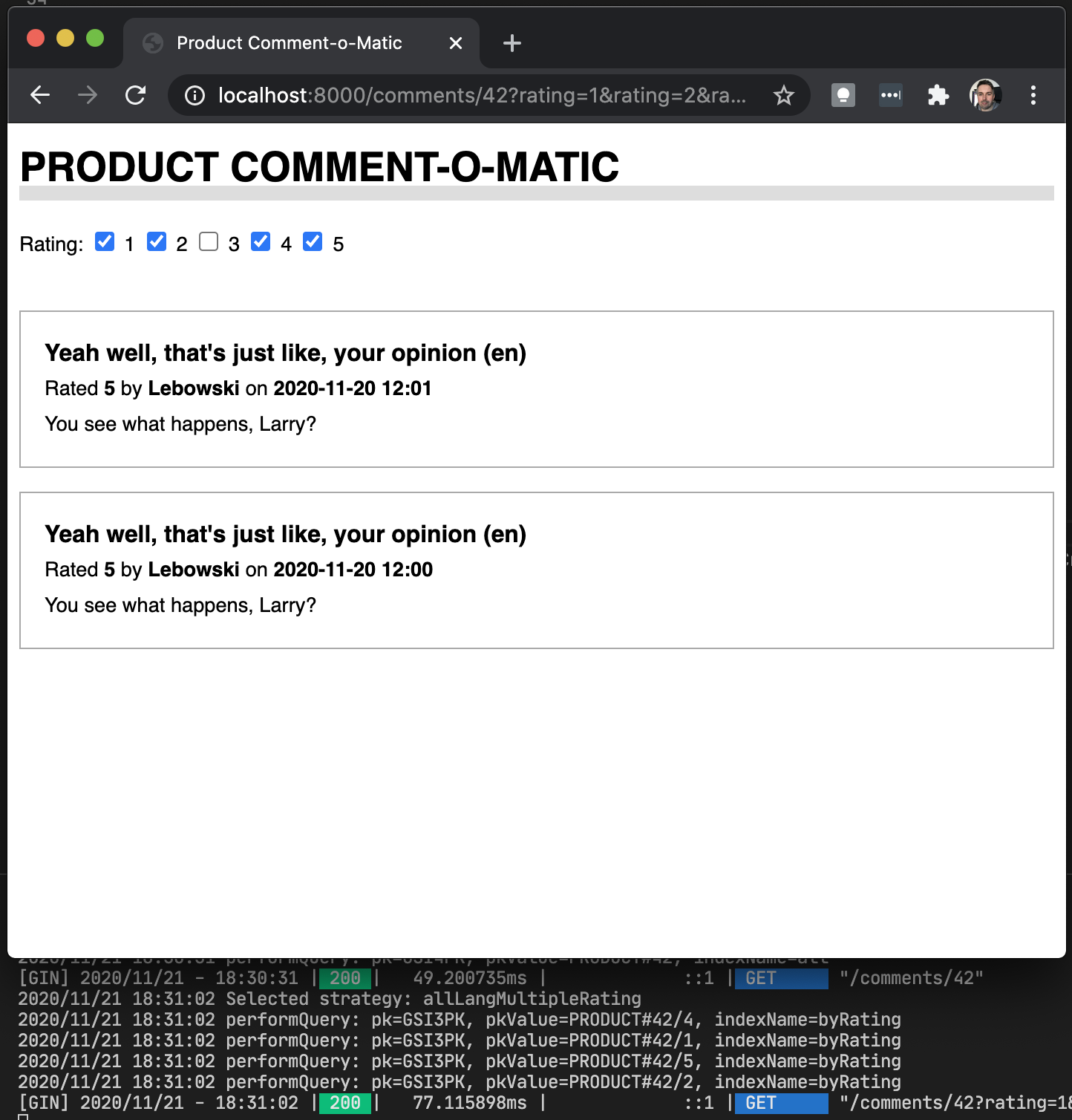
Discussion
You might have noticed that we’re fetching more data than we return in AP3. Page size is 20 comments, yet we are loading 20 * number_of_rating_values, so [1, 2, 3, 4] would load up to 80 comments, throwing away 60. We overscan so that we can be sure we have enough records from each rating to fill up the page, after the combined results have been sorted by date. (As explained earlier, for [1, 2, 3, 4, 5], the filter is a no-op, so our query planner will bypass this and use a more optimal index.)
You might think that it would be more efficient to perform a query to get 60 keys and then do a BatchGetItem on the top 20. This will cost more as a BatchGetItem charges a minimum of one read capacity unit (RCU) per item, allowing us to read a single item up to 4KB. A comment will be nowhere near that big, so this approach would be wasteful. A query, on the other hand, consumes RCUs based on the actual data read, allowing us to read at least ten comments with a single RCU.
To maximise how many comments we can read in an RCU, large or complex payloads (such as a nested map) that can remain opaque to DynamoDB could be serialized as a protobuf, or similar. This might reduce consumed read capacity units as the same nested attribute names do not have to be included in each item, just the data itself. This has the drawback of making the data illegible in the DynamoDB console and other tools. It also means additional work in ensuring that the serialized value can be correctly deserialized as its schema evolves. That said, this approach should benchmarked to understand the benefits it might bring.
In addition, a product may have comments with only 5 and 1 ratings. There is no point in looking for other ratings. We can improve on these potentially wasted calls by maintaining counters for each rating. A query for comments with rating 3 can be skipped if the corresponding count is zero. This will be explored in the next post.
Summary
We’ve built a comment filtering solution without needing to use DynamoDB filters and we haven’t needed to duplicate data excessively. We are still duplicating, but are doing so on a far smaller scale. Importantly, the duplication, or rather, index projection, is now handled by DynamoDB. We no longer need Lambda and DynamoDB streams to maintain the table.
This was achieved with global secondary indexes and parallel queries. GSIs automate the projection table items into indexes with different keys, allowing us to organise the data into predefined sets that are cheap to read. Parallel queries allow us to retrieve multiple result sets from DynamoDB all at the same time and merge them, meaning we no longer need to store every possible combination to answer or queries.
The client code is now more complex, but there is a lot of flexibility when DynamoDB and the client work together in unison to provide a data service. Model implementation details should be abstracted. It is essential to encode this logic into a library or API so that all consumers can work at a higher level.
When working with DynamoDB it is better to directly address known access patterns instead of trying to build something overly generic and reusable. We cannot use this model to meet every new access pattern as we might do with a relational database. However, the model is flexible enough to answer more questions efficiently, such as:
- Show the most recent positive and most recent negative comment for a product
- When was a product last commented on?
- …let me know if you spot any others!
Like our original approach, maintaining an index is not not free. Every eligible item written to the table is also written to the index. In the next post, we will look more closely at pagination.
Thanks for following along so far!
The NoSQL Workbench model is available for download. NoSQL Workbench is a great tool, try it out if you haven’t already.
Comments and corrections are welcome. I am working on making the diagrams exported from NoSQL Workbench more accessible.